Power BI entfaltet sein volles Potenzial erst dann, wenn das zugrunde liegende Datenmodell sauber aufgebaut ist. Wer Dataset-Architektur, Measures und die Zentralisierung von wichtigen Logiken von Anfang an strukturiert angeht, spart später erheblichen Pflegeaufwand – und vermeidet die typischen Fehler, die in gewachsenen Projekten schwer rückgängig zu machen sind. Dieser Artikel gibt einen Überblick über die wichtigsten Best Practices.
1. Datenmodellierung: der richtige Einstieg
Ein sauberes semantisches Modell folgt dem Star oder Snowflake Schema: Dimensionstabellen horizontal oben, Faktentabellen vertikal darunter geben einen guten Überblick. Die Tabellen werden optimalerweise über eindeutige IDs miteinander verbunden. M:N-Beziehungen und bidirektionale Filter sollten konsequent vermieden werden: sie erzeugen schwer vorhersehbares Filterverhalten und sind eine häufige Ursache für fehlerhafte DAX-Ergebnisse. Dieses Grundprinzip bestimmt alle weiteren Entscheidungen im Modellaufbau.
Dabei enthält das Modell nur die Spalten, die tatsächlich in den Reports benötigt werden. Unnötige Felder erhöhen die Modellgröße und erschweren die Orientierung – sowohl für Entwickler als auch für Endnutzer (im Falle des Self-Service-Ansatzes).
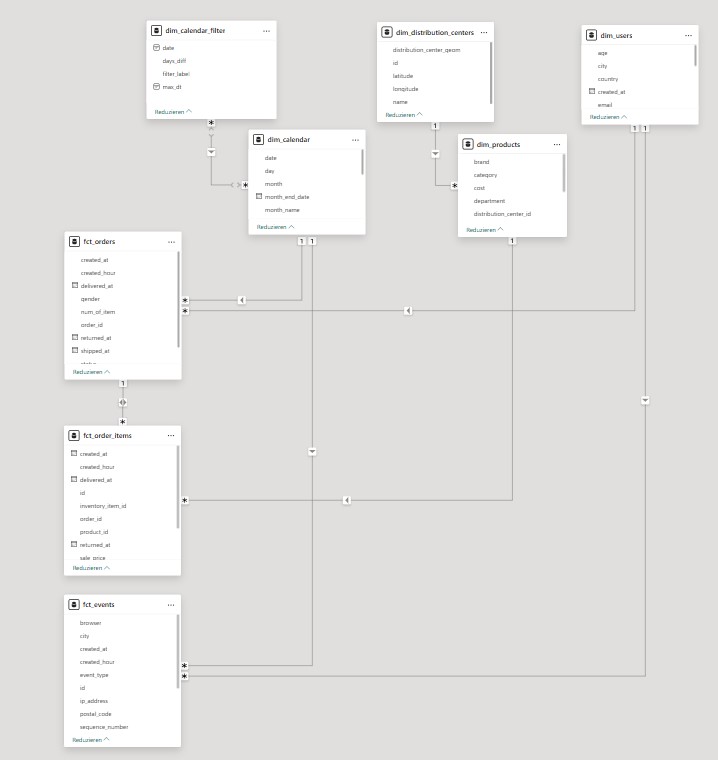
2. Eine zentrale Datumstabelle für alle Datasets
Eine zentral verwaltete Datumstabelle – ob in der Quelldatenbank oder im Dataflow – sollte allen Datasets als gemeinsame Quelle zur Verfügung stehen. Das zentralisiert die Logik und hält sie aus dem semantischen Modell heraus.
Sie ist gleich aus zwei Gründen unverzichtbar: Zum einen setzen DAX-Zeitintelligenzfunktionen wie SAMEPERIODLASTYEAR oder TOTALYTD eine lückenlose, markierte Datumstabelle voraus. Zum anderen ist sie der einzige saubere Weg, mehrere Faktentabellen mit unterschiedlichen Datumsspalten über eine gemeinsame Dimension miteinander zu verknüpfen.
3. Calculation Groups für konsistente Berechnungslogik
Calculation Groups sind eine Erweiterung des semantischen Modells, die es ermöglichen, eine Menge von Berechnungsmodifikationen als eigene Dimension abzubilden. Anstatt für jede Zeitintelligenz-Variante – etwa YTD, MAT oder Vorjahresvergleich – ein separates Measure zu erstellen, definiert eine Calculation Group diese Varianten einmalig als Calculation Items. Jedes Item enthält eine DAX-Formel, die auf das jeweils aufgerufene Basismeasure angewendet wird. Das Ergebnis: dieselbe Zeitlogik steht automatisch für jedes Measure im Modell zur Verfügung, ohne dass Duplikation entsteht.
Seit dem nativen Support in der Modellansicht von Power BI Desktop können Calculation Groups direkt im Tool erstellt und verwaltet werden – ohne Umweg über externe Editoren wie Tabular Editor.
4. UDFs für komplexe und wiederkehrende Berechnungslogik
UDFs – User Defined Functions – kapseln Logik, die sich im Modell wiederholt oder an mehreren Stellen gebraucht wird, in einer einzigen, benannten Funktion. Das können einfache Hilfsberechnungen sein, aber auch komplexere Logiken wie Forecasting-Algorithmen, Ranking-Techniken oder die Generierung von SVG-basierten Visuals per DAX.
Auch innerhalb eines Calculation Items lassen sich UDFs aufrufen, was die Kombination beider Konzepte besonders leistungsfähig macht. Eine Änderung an der UDF wirkt sich sofort auf alle Aufrufer aus – ohne dass einzelne Measures manuell angepasst werden müssen.
5. Measures gezielt strukturieren und gruppieren
Bewährt hat sich eine dedizierte, datenlose Measure-Tabelle – getrennt von den eigentlichen Datentabellen. Innerhalb dieser Tabelle werden Measures in thematischen Ordnern organisiert, etwa nach Geschäftsbereichen, Zeiträumen oder Berechnungstypen wie Base Measures, Ratio Measures oder Time Intelligence.
Genauso wichtig ist die interne Hierarchie: Komplexe KPIs bauen auf einfachen Basismeasures auf, anstatt dieselbe Logik mehrfach zu verschachteln. Verhält sich ein KPI unerwartet, lässt sich die Ursache so schrittweise durch die Measure-Hierarchie verfolgen.

6. Field Parameters: Kennzahlen und Dimensionen dynamisch steuern
Field Parameters ermöglichen es, die in einem Visual angezeigte Kennzahl oder Dimension dynamisch per Slicer steuern zu lassen. Ein Report kann so mit einer einzigen Visualisierung mehrere Szenarien abdecken, anstatt für jede Metrik oder Dimension ein separates Visual zu erstellen.
Field Parameters erzeugen im Hintergrund eine DAX-Tabelle mit einer festen Struktur. Wer diese Struktur versteht, kann Field Parameters gezielt und flexibel einsetzen – und weiß gleichzeitig, wo ihre Grenzen liegen.
7. Naming Conventions
Konsistente Benennungen für Tabellen, Spalten, Measures und Ordner sind keine Ästhetikfrage – sie entscheiden darüber, ob ein Modell von anderen Entwicklern verstanden und weiterentwickelt werden kann. Bewährt haben sich klare Präfixe und Konventionen: Dimensionstabellen etwa mit „dim_“ , Faktentabellen mit „fct_“ , versteckte Hilfstabellen mit einem Unterstrich.
Besonders wichtig ist, diese Konventionen von Anfang an festzulegen. Nachträgliche Umbenennungen können bestehende Reportverknüpfungen beschädigen – insbesondere wenn mehrere Reports per Live Connection auf dasselbe Semantic Model zugreifen.
8. Dataset & Report trennen
Ein zentrales Semantic Model, auf das mehrere Reports per Live Connection zugreifen, vermeidet redundante Logik und stellt sicher, dass Änderungen an der Datenlogik automatisch in alle abhängigen Reports einfließen. Wie die Arbeitsteilung zwischen Power BI Desktop und Power BI Service dabei konkret aussieht, wurde bereits in einem früheren Beitrag erläutert.
Fazit
Ein nachhaltig aufgebautes semantisches Modell beginnt mit einer sauberen Datenmodellierung. Calculation Groups und UDFs sorgen dafür, dass Berechnungslogik einmalig definiert und im gesamten Modell wiederverwendet wird. Strukturiert abgelegte Measures und der gezielte Einsatz von Field Parameters schaffen Übersicht und Flexibilität im Report. Naming Conventions und die konsequente Trennung von Dataset und Report runden das Fundament ab und stellen sicher, dass das Modell langfristig wartbar und nachvollziehbar bleibt.
Bei der Umsetzung dieser Best Practices wird gerne unterstützt – ob als einmalige Beratung oder im Rahmen eines laufenden Projekts. Kontaktiere uns gerne!